BLOG
Implementing Transfer Learning to Optimize an Edge AI Device
Over the past decade, machine learning for object detection has reached a level where high accuracy is now a customer expectation, and having an AI model that is representative and consistent is often a key concern. If you’re implementing edge AI on your own computer vision product–whether it’s for catching anomalies in a production line or estimating populations of animal species–and your device still can’t tell a grizzly bear from a fire hydrant, then the data your object detection model was trained on may be an issue.
One useful method of improving the performance of an existing object detection model is transfer learning. It can also be used as a starting point for identifying unique objects, instead of building a new model from scratch. In this post, we’ll share how MistyWest used the Edge Impulse platform to fine-tune the YOLOv5s model to perform inferencing: to identify cars, trucks, and buses using our off-the-shelf (OTS) edge AI device, MistySOM – and how our retrained model outperformed the general model when it was put to the test.
How to fine-tune your object detection model
Fine-tuning an object detection model means training it on data that is similar to the targeted application, in similar conditions, at the same camera angle, using the same camera. The stock YOLOv5s model (which we’ll refer to as the Generic YOLO from here forward) performs well for a basic object detection model. By retraining it on our own traffic video data using transfer learning, we can improve its overall performance and better identify different types of vehicles.

Left to right: MistySOM; MistyCarrier board, with a wide range of peripherals for evaluation and testing of the SoM’s capabilities
To retrain our own traffic data, we prepared our data capture device. The traffic camera is connected to MistySOM, an edge AI solution based on the Renesas RZ/V2L microprocessor. MistySOM contains Renesas’s Dynamically Reconfigurable Processor (DRP-AI accelerator), a powerful NPU ideal for object detection applications. Captured data is uploaded to the Edge Impulse platform, which handles the entire ML pipeline – uploading data, labelling, training, and deployment. Their platform is also compatible with a wide range of other hardware solutions.
Once the video data is captured using MistySOM, it is converted into images using the FFmpeg tool and uploaded to Edge Impulse’s dashboard. We worked with a small dataset of about 1,000 images, labelling them into three categories: cars, trucks, and buses. Edge Impulse simplifies labelling by allowing you to use another object detection model or your own model to auto-label objects, which you can then review and adjust. Once labelling is complete, the data is used to fine-tune the YOLO model with transfer learning using the EON tuner tool, which helps quickly compare configurations to find the optimal model architecture.
Once your new model is ready, you can download it from the Edge Impulse dashboard in various formats; in our case, a Renesas DRP-AI deployment of the model which consists of C++ source code, containing the model as well as the camera reading and display. Since the camera and display functionalities are already taken care of using GStreamer, we prepared a python script to just extract the model binaries. These binaries were used by our DRP-AI Gstreamer plugin in the middle of a GStreamer pipeline, giving us live inferencing outputs.
Et voilà! After completing these steps, our new and fine-tuned model ran on MistySoM.
The numbers: how fine-tuning improves model performance
To compare apples with apples, and to see how much performance improved, we recorded a video from the camera connected to MistySoM, then ran separate inferencing on the Generic YOLO and the fine-tuned YOLOv5s model on the same video. We compared the two models across a variety of commonly used metrics, such as the CPU usage of the SoM while running the model, how many frames per second the model was able to process using the DRP-AI module (DRP-AI FPS), the power consumption of the SoM while running the models, and the model size.
We can see from Table 1 that, aside from a slight increase in power consumption, the fine-tuned model outperformed the Generic YOLO with lower CPU usage, more than double the frame rate, and the same model size.
Table 1: comparing metric improvements between models
Moreover, using an IoU threshold of 0.5, we can see from Chart 1 that the fine-tuned model resulted in improvements in precision, recall, and F-score compared to the Generic YOLO.
Chart 1: How precision, recall and f-score performed for each object detection model
Individual frame comparisons between the stock and fine-tuned model
In our specific application, as the fine-tuned model has been trained on MistyWest’s data taken with the same camera, camera angle, and weather conditions as the test data, it better identifies objects. To ensure frame comparisons are fair, we slowed the video down for the inferencing so that inferencing runs on every frame of the video without skips caused by inferencing times. We ensured the video frame rate has an equal number to the DRP-AI rate (inference speed) as shown in the top-left-hand corner of the following frame comparisons.
In frame comparisons below, the left frame shows the Generic YOLO and the right frame is the fine-tuned YOLOv5s model. The percentages shown above each detected object in red boxes are the confidence scores reflecting how confident the model is for correctly identifying the object. When running the video in real-time at 30 frames per second, we measured inference speeds of 2.5 and 6.2 FPS for the stock and fine-tuned models, respectively.


Frame Comparison 1
As we see in Frame Comparison 1, in Generic YOLO, the ‘person’ class is still included, the bus stop is misidentified as a truck, and the car behind the bus stop is not identified. The fine-tuned model, however, identified the car behind the bus stop as it has been trained to identify cars in this position; the bus stop is also not misidentified as a truck; the person is not identified as the ‘person’ class is not included in the model.

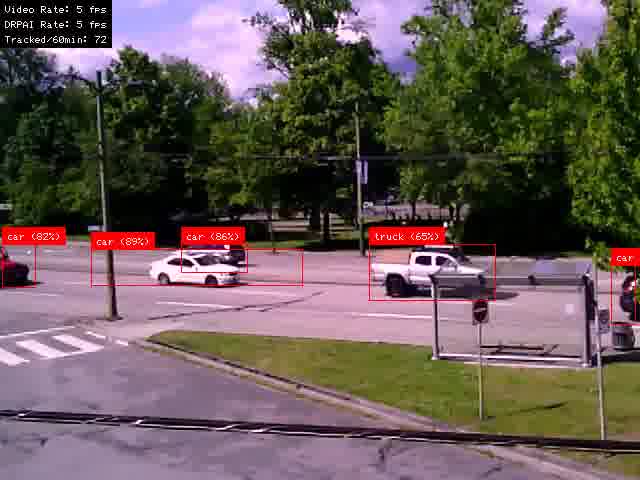
Frame Comparison 2
In Frame Comparison 2, the Generic YOLO misidentifies the stop sign as a traffic light and also doesn’t identify the car to the right of the bus stop. The fine-tuned model has an overly large bounding box on one car, but does identify the car to the right of the bus stop, and doesn’t include the ‘traffic light’ class.


Frame Comparison 3
In Frame Comparison 3, the Generic YOLO misidentifies the bus stop as a truck again, identifies two cars as just one, and adds two bounding boxes around one car. The bus stop is not misidentified in the fine-tuned model, and it identifies all cars in the image, albeit with imperfect bounding boxes, which can most likely be improved by additional data and training.


Frame Comparison 4
Finally, in Frame Comparison 4, the Generic YOLO fails to identify any of the cars behind the bus stop. Whereas the fine-tuned model correctly identifies 2 of 3 cars behind the bus stop which adds more evidence that with more data and training, this result can be further improved.
Conclusion
Transfer learning opens up a world of possibilities for expedited training of machine learning models. Fine-tuning pre-existing models like YOLOv5s improves performance to not only yield more accurate results, but to enable engineers to focus more on ideas instead of their implementation.
Utilizing off-the-shelf edge AI solutions like MistySOM with software like Edge Impulse allows for quick verification during the prototyping process. This rapid iteration can be crucial for reducing product development timelines so you can have a more efficient and successful product launch and stay ahead of the competition.
If you’re optimizing your computer vision product for greater accuracy, fill out the form below or send a message to mistysom@mistywest.com and ask how MistyWest can provide fast and effective support as your project moves from prototyping to high-volume chip-down design.